Chapter 1: Sampling and Data
1.3 Frequency, Frequency Tables, and Levels of Measurement
Learning Objectives
By the end of this section, the student should be able to:
- Determine the level of measurements for variables.
- Create and interpret frequency tables.
Once you have a set of data, you will need to organize it so that you can analyze how frequently each datum occurs in the set. However, when calculating the frequency, you may need to round your answers so that they are as precise as possible.
Answers and Rounding Off
A simple way to round off answers is to carry your final answer one more decimal place than was present in the original data. Round off only the final answer. Do not round off any intermediate results, if possible. If it becomes necessary to round off intermediate results, carry them to at least twice as many decimal places as the final answer. For example, the average of the three quiz scores four, six, and nine is 6.3, rounded off to the nearest tenth, because the data are whole numbers. Most answers will be rounded off in this manner.
It is not necessary to reduce most fractions in this course. Especially in Chapter 3: Probability Topics, it is more helpful to leave an answer as an unreduced fraction.
Levels of Measurement
The way a set of data is measured is called its level of measurement. Correct statistical procedures depend on a researcher being familiar with levels of measurement. Not every statistical operation can be used with every set of data. Data can be classified into four levels of measurement. They are (from lowest to highest level):
- Nominal scale level
- Ordinal scale level
- Interval scale level
- Ratio scale level
Data that is measured using a nominal scale is qualitative. Categories, colors, names, labels and favorite foods along with yes or no responses are examples of nominal level data. Nominal scale data are not ordered. For example, trying to classify people according to their favorite food does not make any sense. Putting pizza first and sushi second is not meaningful.
Smartphone companies are another example of nominal scale data. Some examples are Sony, Motorola, Nokia, Samsung and Apple. This is just a list and there is no agreed upon order. Some people may favor Apple but that is a matter of opinion. Nominal scale data cannot be used in calculations.
Data that is measured using an ordinal scale is similar to nominal scale data but there is a big difference. The ordinal scale data can be ordered. An example of ordinal scale data is a list of the top five national parks in the United States. The top five national parks in the United States can be ranked from one to five but we cannot measure differences between the data.
Another example of using the ordinal scale is a cruise survey where the responses to questions about the cruise are “excellent,” “good,” “satisfactory,” and “unsatisfactory.” These responses are ordered from the most desired response to the least desired. But the differences between two pieces of data cannot be measured. Like the nominal scale data, ordinal scale data cannot be used in calculations.
Data that is measured using the interval scale is similar to ordinal level data because it has a definite ordering but there is a difference between data. The differences between interval scale data can be measured, though the data does not have a starting point.
Temperature scales like Celsius (C) and Fahrenheit (F) are measured by using the interval scale. In both temperature measurements, 40° is equal to 100° minus 60°. Differences make sense. But 0 degrees does not because, in both scales, 0 is not the absolute lowest temperature. Temperatures like -10° F and -15° C exist and are colder than 0.
Interval level data can be used in calculations, but one type of comparison cannot be done. 80° C is not four times as hot as 20° C (nor is 80° F four times as hot as 20° F). There is no meaning to the ratio of 80 to 20 (or four to one).
Data that is measured using the ratio scale takes care of the ratio problem and gives you the most information. Ratio scale data is like interval scale data, but it has a 0 point and ratios can be calculated. For example, four multiple choice statistics final exam scores are 80, 68, 20 and 92 (out of a possible 100 points). The exams are machine-graded.
The data can be put in order from lowest to highest: 20, 68, 80, 92.
The differences between the data have meaning. The score 92 is more than the score 68 by 24 points.
Ratios can be calculated. The smallest score is 0. So 80 is four times 20. The score of 80 is four times better than the score of 20.
Frequency
Twenty students were asked how many hours they worked per day. Their responses, in hours, are as follows: 5, 6, 3, 3, 2, 4, 7, 5, 2, 3, 5, 6, 5, 4, 4, 3, 5, 2, 5, 3.
The table below lists the different data values in ascending order and their frequencies.
| DATA VALUE | FREQUENCY |
|---|---|
| 2 | 3 |
| 3 | 5 |
| 4 | 3 |
| 5 | 6 |
| 6 | 2 |
| 7 | 1 |
A frequency is the number of times a value of the data occurs. According to [link], there are three students who work two hours, five students who work three hours, and so on. The sum of the values in the frequency column, 20, represents the total number of students included in the sample.
A relative frequency is the ratio (fraction or proportion) of the number of times a value of the data occurs in the set of all outcomes to the total number of outcomes. To find the relative frequencies, divide each frequency by the total number of students in the sample—in this case, 20. Relative frequencies can be written as fractions, percentages, or decimals.
| DATA VALUE | FREQUENCY | RELATIVE FREQUENCY |
|---|---|---|
| 2 | 3 | [latex]\frac{3}{20}[/latex] or 0.15 |
| 3 | 5 | [latex]\frac{5}{20}[/latex] or 0.25 |
| 4 | 3 | [latex]\frac{3}{20}[/latex] or 0.15 |
| 5 | 6 | [latex]\frac{6}{20}[/latex] or 0.30 |
| 6 | 2 | [latex]\frac{2}{20}[/latex] or 0.10 |
| 7 | 1 | [latex]\frac{1}{20}[/latex] or 0.05 |
The sum of the values in the relative frequency column of the table is [latex]\frac{20}{20}[/latex], or 1.
Cumulative relative frequency is the accumulation of the previous relative frequencies. To find the cumulative relative frequencies, add all the previous relative frequencies to the relative frequency for the current row, as shown in the table below.
| DATA VALUE | FREQUENCY | RELATIVE FREQUENCY | CUMULATIVE RELATIVE FREQUENCY |
|---|---|---|---|
| 2 | 3 | [latex]\frac{3}{20}[/latex] or 0.15 |
[latex]0.15[/latex] |
| 3 | 5 | [latex]\frac{5}{20}[/latex] or 0.25 |
[latex]0.15 + 0.25 = 0.40[/latex] |
| 4 | 3 | [latex]\frac{3}{20}[/latex] or 0.15 |
[latex]0.40 + 0.15 = 0.55[/latex] |
| 5 | 6 | [latex]\frac{6}{20}[/latex] or 0.30 |
[latex]0.55 + 0.30 = 0.85[/latex] |
| 6 | 2 | [latex]\frac{2}{20}[/latex] or 0.10 |
[latex]0.85 + 0.10 = 0.95[/latex] |
| 7 | 1 | [latex]\frac{1}{20}[/latex] or 0.05 |
[latex]0.95 + 0.05 = 1.00[/latex] |
The last entry of the cumulative relative frequency column is one, indicating that one hundred percent of the data has been accumulated.
Note
Because of rounding, the relative frequency column may not always sum to one, and the last entry in the cumulative relative frequency column may not be one. However, they each should be close to one.
The table below represents the heights, in inches, of a sample of 100 male semiprofessional soccer players.
| HEIGHTS (INCHES) | FREQUENCY | RELATIVE FREQUENCY | CUMULATIVE RELATIVE FREQUENCY |
|---|---|---|---|
| 59.95–61.95 | 5 | [latex]\frac{5}{100}=0.05[/latex] | [latex]0.05[/latex] |
| 61.95–63.95 | 3 | [latex]\frac{3}{100}=0.03[/latex] | [latex]0.05 + 0.03 = 0.08[/latex] |
| 63.95–65.95 | 15 | [latex]\frac{15}{100}=0.15[/latex] | [latex]0.08 + 0.15 = 0.23[/latex] |
| 65.95–67.95 | 40 | [latex]\frac{40}{100}=0.40[/latex] | [latex]0.23 + 0.40 = 0.63[/latex] |
| 67.95–69.95 | 17 | [latex]\frac{17}{100}=0.17[/latex] | [latex]0.63 + 0.17 = 0.80[/latex] |
| 69.95–71.95 | 12 | [latex]\frac{12}{100}=0.12[/latex] | [latex]0.80 + 0.12 = 0.92[/latex] |
| 71.95–73.95 | 7 | [latex]\frac{7}{100}=0.07[/latex] | [latex]0.92 + 0.07 = 0.99[/latex] |
| 73.95–75.95 | 1 | [latex]\frac{1}{100}=0.01[/latex] | [latex]0.99 + 0.01 = 1.00[/latex] |
| Total = 100 | Total = 1.00 |
The data in this table have been grouped into the following intervals:
- 59.95 to 61.95 inches
- 61.95 to 63.95 inches
- 63.95 to 65.95 inches
- 65.95 to 67.95 inches
- 67.95 to 69.95 inches
- 69.95 to 71.95 inches
- 71.95 to 73.95 inches
- 73.95 to 75.95 inches
Note
This example is used again in Descriptive Statistics, where the method used to compute the intervals will be explained.
In this sample, there are five players whose heights fall within the interval 59.95–61.95 inches, three players whose heights fall within the interval 61.95–63.95 inches, 15 players whose heights fall within the interval 63.95–65.95 inches, 40 players whose heights fall within the interval 65.95–67.95 inches, 17 players whose heights fall within the interval 67.95–69.95 inches, 12 players whose heights fall within the interval 69.95–71.95, seven players whose heights fall within the interval 71.95–73.95, and one player whose heights fall within the interval 73.95–75.95. All heights fall between the endpoints of an interval and not at the endpoints.
Example
From the Frequency Table of Soccer Player Height, find the percentage of heights that are less than 65.95 inches.
Solution
If you look at the first, second, and third rows, the heights are all less than 65.95 inches. There are 5 + 3 + 15 = 23 players whose heights are less than 65.95 inches. The percentage of heights less than 65.95 inches is then [latex]\frac{23}{100}[/latex] or 23%. This percentage is the cumulative relative frequency entry in the third row.
Your Turn!
The table below shows the amount, in inches, of annual rainfall in a sample of towns.
| Rainfall (Inches) | Frequency | Relative Frequency | Cumulative Relative Frequency |
|---|---|---|---|
| 2.95–4.97 | 6 | [latex]\frac{6}{50}=0.12[/latex] | [latex]0.12[/latex] |
| 4.97–6.99 | 7 | [latex]\frac{7}{50}=0.14[/latex] | [latex]0.12 + 0.14 = 0.26[/latex] |
| 6.99–9.01 | 15 | [latex]\frac{15}{50}=0.30[/latex] | [latex]0.26 + 0.30 = 0.56[/latex] |
| 9.01–11.03 | 8 | [latex]\frac{8}{50}=0.16[/latex] | [latex]0.56 + 0.16 = 0.72[/latex] |
| 11.03–13.05 | 9 | [latex]\frac{9}{50}=0.18[/latex] | [latex]0.72 + 0.18 = 0.90[/latex] |
| 13.05–15.07 | 5 | [latex]\frac{5}{50}=0.10[/latex] | [latex]0.90 + 0.10 = 1.00[/latex] |
| Total = 50 | Total = 1.00 |
From the frequency table, find the percentage of rainfall that is less than 9.01 inches.
Solution
0.56 or 56%
From the frequency table, find the percentage of heights that fall between 61.95 and 65.95 inches.
Solution
Add the relative frequencies in the second and third rows: [latex]0.03 + 0.15 = 0.18[/latex] or 18%.
From the frequency table, find the percentage of rainfall that is between 6.99 and 13.05 inches.
Solution
0.30 + 0.16 + 0.18 = 0.64 or 64%
Your Turn!
Use the heights of the 100 male semiprofessional soccer players in the table above. Fill in the blanks and check your answers.
- The percentage of heights that are from 67.95 to 71.95 inches is [latex]\underline{\hspace{2cm}}[/latex].
- The percentage of heights that are from 67.95 to 73.95 inches is [latex]\underline{\hspace{2cm}}[/latex].
- The percentage of heights that are more than 65.95 inches is [latex]\underline{\hspace{2cm}}[/latex].
- The number of players in the sample who are between 61.95 and 71.95 inches tall is [latex]\underline{\hspace{2cm}}[/latex].
- What kind of data are the heights?
- Describe how you could gather this data (the heights) so that the data are characteristic of all male semiprofessional soccer players.
Remember, you count frequencies. To find the relative frequency, divide the frequency by the total number of data values. To find the cumulative relative frequency, add all of the previous relative frequencies to the relative frequency for the current row.
Solution
- 29%
- 36%
- 77%
- 87
- quantitative continuous
- get rosters from each team and choose a simple random sample from each
Your Turn!
From the frequency table in the exercise about rainfall, find the number of towns that have rainfall between 2.95 and 9.01 inches.
Solution
[latex]6 + 7 + 15 = 28 \text{towns}[/latex]
Your Turn!
Nineteen people were asked how many miles, to the nearest mile, they commute to work each day. The data are as follows:
2; 5; 7; 3; 2; 10; 18; 15; 20; 7; 10; 18; 5; 12; 13; 12; 4; 5; 10. The following table was produced:
| DATA | FREQUENCY | RELATIVE
FREQUENCY |
CUMULATIVE
RELATIVE FREQUENCY |
|---|---|---|---|
| 3 | 3 | [latex]\frac{3}{19}[/latex] | 0.1579 |
| 4 | 1 | [latex]\frac{1}{19}[/latex] | 0.2105 |
| 5 | 3 | [latex]\frac{3}{19}[/latex] | 0.1579 |
| 7 | 2 | [latex]\frac{2}{19}[/latex] | 0.2632 |
| 10 | 3 | [latex]\frac{4}{19}[/latex] | 0.4737 |
| 12 | 2 | [latex]\frac{2}{19}[/latex] | 0.7895 |
| 13 | 1 | [latex]\frac{1}{19}[/latex] | 0.8421 |
| 15 | 1 | [latex]\frac{1}{19}[/latex] | 0.8948 |
| 18 | 1 | [latex]\frac{1}{19}[/latex] | 0.9474 |
| 20 | 1 | [latex]\frac{1}{19}[/latex] | 1.0000 |
- Is the table correct? If it is not correct, what is wrong?
- True or False: Three percent of the people surveyed commute three miles. If the statement is not correct, what should it be? If the table is incorrect, make the corrections.
- What fraction of the people surveyed commute five or seven miles?
- What fraction of the people surveyed commute 12 miles or more? Less than 12 miles? Between five and 13 miles (not including five and 13 miles)?
Solution
-
- No. The frequency column sums to 18, not 19. Not all cumulative relative frequencies are correct.
- False. The frequency for three miles should be one; for two miles (left out), two. The cumulative relative frequency column should read: 0.1052, 0.1579, 0.2105, 0.3684, 0.4737, 0.6316, 0.7368, 0.7895, 0.8421, 0.9474, 1.0000.
- [latex]\frac{5}{19}[/latex]
- [latex]\frac{7}{19}[/latex], [latex]\frac{12}{19}[/latex], [latex]\frac{7}{19}[/latex]
Your Turn!
The rainfall frequency table represents the amount, in inches, of annual rainfall in a sample of towns. What fraction of towns surveyed get between 11.03 and 13.05 inches of rainfall each year?
Solution
[latex]\frac{9}{50}[/latex]
Your Turn!
The table below contains the total number of deaths worldwide as a result of earthquakes for the period from 2000 to 2012.
| Year | Total Number of Deaths |
|---|---|
| 2000 | 231 |
| 2001 | 21,357 |
| 2002 | 11,685 |
| 2003 | 33,819 |
| 2004 | 228,802 |
| 2005 | 88,003 |
| 2006 | 6,605 |
| 2007 | 712 |
| 2008 | 88,011 |
| 2009 | 1,790 |
| 2010 | 320,120 |
| 2011 | 21,953 |
| 2012 | 768 |
| Total | 823,856 |
Answer the following questions.
- What is the frequency of deaths measured from 2006 through 2009?
- What percentage of deaths occurred after 2009?
- What is the relative frequency of deaths that occurred in 2003 or earlier?
- What is the percentage of deaths that occurred in 2004?
- What kind of data are the numbers of deaths?
- The Richter scale is used to quantify the energy produced by an earthquake. Examples of Richter scale numbers are 2.3, 4.0, 6.1, and 7.0. What kind of data are these numbers?
Solution
- 97,118 (11.8%)
- 41.6%
- 67,092/823,856 or 0.081 or 8.1 %
- 27.8%
- Quantitative discrete
- Quantitative continuous
Your Turn!
The table below contains the total number of fatal motor vehicle traffic crashes in the United States for the period from 1994 to 2011.
| Year | Total Number of Crashes | Year | Total Number of Crashes |
|---|---|---|---|
| 1994 | 36,254 | 2004 | 38,444 |
| 1995 | 37,241 | 2005 | 39,252 |
| 1996 | 37,494 | 2006 | 38,648 |
| 1997 | 37,324 | 2007 | 37,435 |
| 1998 | 37,107 | 2008 | 34,172 |
| 1999 | 37,140 | 2009 | 30,862 |
| 2000 | 37,526 | 2010 | 30,296 |
| 2001 | 37,862 | 2011 | 29,757 |
| 2002 | 38,491 | Total | 653,782 |
| 2003 | 38,477 |
Answer the following questions.
- What is the frequency of deaths measured from 2000 through 2004?
- What percentage of deaths occurred after 2006?
- What is the relative frequency of deaths that occurred in 2000 or before?
- What is the percentage of deaths that occurred in 2011?
- What is the cumulative relative frequency for 2006? Explain what this number tells you about the data.
Solution
- 190,800 (29.2%)
- 24.9%
- 260,086/653,782 or 39.8%
- 4.6%
- 75.1% of all fatal traffic crashes for the period from 1994 to 2011 happened from 1994 to 2006.
Section 1.3 Review
Some calculations generate numbers that are artificially precise. It is not necessary to report a value to eight decimal places when the measures that generated that value were only accurate to the nearest tenth. Round off your final answer to one more decimal place than was present in the original data. This means that if you have data measured to the nearest tenth of a unit, report the final statistic to the nearest hundredth.
In addition to rounding your answers, you can measure your data using the following four levels of measurement.
- Nominal scale level: data that cannot be ordered nor can it be used in calculations
- Ordinal scale level: data that can be ordered; the differences cannot be measured
- Interval scale level: data with a definite ordering but no starting point; the differences can be measured, but there is no such thing as a ratio.
- Ratio scale level: data with a starting point that can be ordered; the differences have meaning and ratios can be calculated.
When organizing data, it is important to know how many times a value appears. How many statistics students study five hours or more for an exam? What percent of families on our block own two pets? Frequency, relative frequency, and cumulative relative frequency are measures that answer questions like these.
Section 1.3 Practice
What type of measure scale is being used? Nominal, ordinal, interval or ratio.
- High school soccer players classified by their athletic ability: Superior, Average, Above average
- Baking temperatures for various main dishes: 350, 400, 325, 250, 300
- The colors of crayons in a 24-crayon box
- Social security numbers
- Incomes measured in dollars
- A satisfaction survey of a social website by number: 1 = very satisfied, 2 = somewhat satisfied, 3 = not satisfied
- Political outlook: extreme left, left-of-center, right-of-center, extreme right
- Time of day on an analog watch
- The distance in miles to the closest grocery store
- The dates 1066, 1492, 1644, 1947, and 1944
- The heights of 21–65 year-old women
- Common letter grades: A, B, C, D, and F
Solution
- ordinal
- interval
- nominal
- nominal
- ratio
- ordinal
- nominal
- interval
- ratio
- interval
- ratio
- ordinal
Fifty part-time students were asked how many courses they were taking this term. The (incomplete) results are shown below:
| # of Courses | Frequency | Relative Frequency | Cumulative Relative Frequency |
|---|---|---|---|
| 1 | 30 | 0.6 | |
| 2 | 15 | ||
| 3 |
- Fill in the blanks in the Part-time Student Course Loads table.
- What percent of students take exactly two courses?
- What percent of students take one or two courses?
Solution
1.
| # of Courses | Frequency | Relative Frequency | Cumulative Relative Frequency |
|---|---|---|---|
| 1 | 30 | 0.6 | 0.6 |
| 2 | 15 | 0.3 | 0.9 |
| 3 | 5 | 0.1 | 1.0 |
2. 30%
3. 90%
Sixty adults with gum disease were asked the number of times per week they used to floss before their diagnosis. The (incomplete) results are shown in the Flossing Frequency for Adults with Gum Disease table.
| # Flossing per Week | Frequency | Relative Frequency | Cumulative Relative Freq. |
|---|---|---|---|
| 0 | 27 | 0.4500 | |
| 1 | 18 | ||
| 3 | 0.9333 | ||
| 6 | 3 | 0.0500 | |
| 7 | 1 | 0.0167 |
- Fill in the blanks in the Flossing Frequency for Adults with Gum Disease table.
- What percent of adults flossed six times per week?
- What percentage flossed at most three times per week?
Solution
-
# Flossing per Week Frequency Relative Frequency Cumulative Relative Frequency 0 27 0.4500 0.4500 1 18 0.3000 0.7500 3 11 0.1833 0.9333 6 3 0.0500 0.9833 7 1 0.0167 1 - 5.00%
- 93.33%
Nineteen immigrants to the U.S were asked how many years, to the nearest year, they have lived in the U.S. The data are as follows: 2; 5; 7; 2; 2; 10; 20; 15; 0; 7; 0; 20; 5; 12; 15; 12; 45; 10.
The Frequency of Immigrant Survey Responses table was produced.
| Data | Frequency | Relative Frequency | Cumulative Relative Frequency |
|---|---|---|---|
| 0 | 2 | [latex]\frac{2}{19}[/latex] | 0.1053 |
| 2 | 3 | [latex]\frac{3}{19}[/latex] | 0.2632 |
| 4 | 1 | [latex]\frac{1}{19}[/latex] | 0.3158 |
| 5 | 3 | [latex]\frac{3}{19}[/latex] | 0.4737 |
| 7 | 2 | [latex]\frac{2}{19}[/latex] | 0.5789 |
| 10 | 2 | [latex]\frac{2}{19}[/latex] | 0.6842 |
| 12 | 2 | [latex]\frac{2}{19}[/latex] | 0.7895 |
| 15 | 1 | [latex]\frac{1}{19}[/latex] | 0.8421 |
| 20 | 1 | [latex]\frac{1}{19}[/latex] | 1.0000 |
- Fix the errors in the Frequency of Immigrant Survey Responses table. Also, explain how someone might have arrived at the incorrect number(s).
- Explain what is wrong with this statement: “47 percent of the people surveyed have lived in the U.S. for 5 years.”
- Fix the statement in b to make it correct.
- What fraction of the people surveyed have lived in the U.S. five or seven years?
- What fraction of the people surveyed have lived in the U.S. at most 12 years?
- What fraction of the people surveyed have lived in the U.S. fewer than 12 years?
- What fraction of the people surveyed have lived in the U.S. from five to 20 years, inclusive?
Solution
- The Frequencies for 15 and 20 should both be two and the Relative Frequencies should both be 2-19
- The mistake could be due to copying the data down wrong. The Cumulative Relative Frequency for five years should be 0.4737. The mistake is due to calculating the Relative Frequency instead of the Cumulative Relative Frequency. The Cumulative Relative Frequency for 15 years should be 0.8947
- The 47% is the Cumulative Relative Frequency, not the Relative Frequency.
47% of the people surveyed have lived in the U.S. for five years or less. - [latex]\frac{5}{19}[/latex]
- [latex]\frac{15}{19}[/latex]
- [latex]\frac{13}{19}[/latex]
- [latex]\frac{13}{19}[/latex]
How much time does it take to travel to work? The Travel Time table shows the mean commute time by state for workers at least 16 years old who are not working at home. Find the mean travel time, and round off the answer properly.
| Travel Time | |||||||||
| 24.0 | 24.3 | 25.9 | 18.9 | 27.5 | 17.9 | 21.8 | 20.9 | 16.7 | 27.3 |
| 18.2 | 24.7 | 20.0 | 22.6 | 23.9 | 18.0 | 31.4 | 22.3 | 24.0 | 25.5 |
| 24.7 | 24.6 | 28.1 | 24.9 | 22.6 | 23.6 | 23.4 | 25.7 | 24.8 | 25.5 |
| 21.2 | 25.7 | 23.1 | 23.0 | 23.9 | 26.0 | 16.3 | 23.1 | 21.4 | 21.5 |
| 27.0 | 27.0 | 18.6 | 31.7 | 23.3 | 30.1 | 22.9 | 23.3 | 21.7 | 18.6 |
Solution
The sum of the travel times is 1,173.1. Divide the sum by 50 to calculate the mean value: 23.462. Because each state’s travel time was measured to the nearest tenth, round this calculation to the nearest hundredth: 23.46.
Forbes magazine published data on the best small firms in 2012. These were firms which had been publicly traded for at least a year, have a stock price of at least $5 per share, and have reported annual revenue between $5 million and $1 billion. The frequency table below shows the ages of the chief executive officers for the first 60 ranked firms.
| Age | Frequency | Relative Frequency | Cumulative Relative Frequency |
|---|---|---|---|
| 40–44 | 3 | ||
| 45–49 | 11 | ||
| 50–54 | 13 | ||
| 55–59 | 16 | ||
| 60–64 | 10 | ||
| 65–69 | 6 | ||
| 70–74 | 1 |
- What is the frequency for CEO ages between 54 and 65?
- What percentage of CEOs are 65 years or older?
- What is the relative frequency of ages under 50?
- What is the cumulative relative frequency for CEOs younger than 55?
- Which graph shows the relative frequency and which shows the cumulative relative frequency?
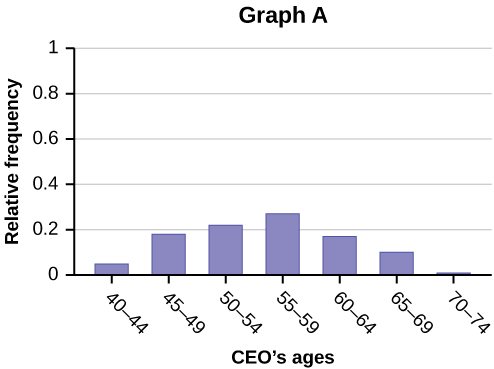
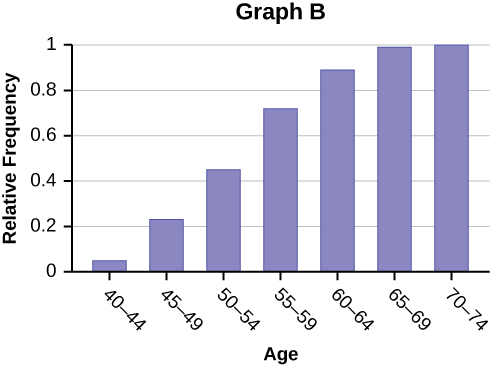
Solution
- 26 (This is the count of CEOs in the 55 to 59 and 60 to 64 categories.)
- 12% (number of CEOs age 65 or older ÷ total number of CEOs)
- 14/60; 0.23; 23%
- 0.45
- Graph A represents the cumulative relative frequency, and Graph B shows the relative frequency.
Use the following information to answer the next two exercises: The Frequency of Hurricane Direct Hits table contains data on hurricanes that have made direct hits on the U.S. Between 1851 and 2004. A hurricane is given a strength category rating based on the minimum wind speed generated by the storm.
| Category | Number of Direct Hits | Relative Frequency | Cumulative Frequency |
|---|---|---|---|
| Total = 273 | |||
| 1 | 109 | 0.3993 | 0.3993 |
| 2 | 72 | 0.2637 | 0.6630 |
| 3 | 71 | 0.2601 | |
| 4 | 18 | 0.9890 | |
| 5 | 3 | 0.0110 | 1.0000 |
1. What is the relative frequency of direct hits that were category 4 hurricanes?
a. 0.0768
b. 0.0659
c. 0.2601
d. Not enough information to calculate
Solution
b
2. What is the relative frequency of direct hits that were AT MOST a category 3 storm?
a. 0.3480
b. 0.9231
c. 0.2601
d. 0.3370
Solution
b
References
“State & County QuickFacts,” U.S. Census Bureau. http://quickfacts.census.gov/qfd/download_data.html (accessed May 1, 2013).
“State & County QuickFacts: Quick, easy access to facts about people, business, and geography,” U.S. Census Bureau. http://quickfacts.census.gov/qfd/index.html (accessed May 1, 2013).
“Table 5: Direct hits by mainland United States Hurricanes (1851-2004),” National Hurricane Center, http://www.nhc.noaa.gov/gifs/table5.gif (accessed May 1, 2013).
“Levels of Measurement,” http://infinity.cos.edu/faculty/woodbury/stats/tutorial/Data_Levels.htm (accessed May 1, 2013).
Courtney Taylor, “Levels of Measurement,” about.com,
http://statistics.about.com/od/HelpandTutorials/a/Levels-Of-Measurement.htm (accessed May 1, 2013).
David Lane. “Levels of Measurement,” Connexions, http://cnx.org/content/m10809/latest/ (accessed May 1, 2013).
the number of times a value of the data occurs
the ratio of the number of times a value of the data occurs in the set of all outcomes to the number of all outcomes to the total number of outcomes
The term applies to an ordered set of observations from smallest to largest. The cumulative relative frequency is the sum of the relative frequencies for all values that are less than or equal to the given value.
