Chapter 10: Linear Regression and Correlation
10.4 Testing the Significance of the Correlation Coefficient
Learning Objectives
By the end of this section, the student should be able to:
- Test the significance of the correlation coefficient.
The correlation coefficient, [latex]r[/latex], tells us about the strength and direction of the linear relationship between [latex]x[/latex] and [latex]y[/latex]. However, the reliability of the linear model also depends on how many observed data points are in the sample. We need to look at both the value of the correlation coefficient [latex]r[/latex] and the sample size [latex]n[/latex], together.
We perform a hypothesis test of the “significance of the correlation coefficient” to decide whether the linear relationship in the sample data is strong enough to use to model the relationship in the population.
The sample data are used to compute [latex]r[/latex], the correlation coefficient for the sample. If we had data for the entire population, we could find the population correlation coefficient. But because we only have sample data, we cannot calculate the population correlation coefficient. The sample correlation coefficient, [latex]r[/latex], is our estimate of the unknown population correlation coefficient.
- The symbol for the population correlation coefficient is [latex]\rho[/latex], the Greek letter “rho.”
- [latex]\rho =[/latex] population correlation coefficient (unknown)
- [latex]r =[/latex] sample correlation coefficient (known; calculated from sample data)
The hypothesis test lets us decide whether the value of the population correlation coefficient [latex]\rho[/latex] is “close to zero” or “significantly different from zero”. We decide this based on the sample correlation coefficient [latex]r[/latex] and the sample size [latex]n[/latex].
If the test concludes that the correlation coefficient is significantly different from zero, we say that the correlation coefficient is “significant.”
If the test concludes that the correlation coefficient is not significantly different from zero (it is close to zero), we say that correlation coefficient is “not significant”.
Note
- If [latex]r[/latex] is significant and the scatter plot shows a linear trend, the line can be used to predict the value of [latex]y[/latex] for values of [latex]x[/latex] that are within the domain of observed [latex]x[/latex] values.
- If [latex]r[/latex] is not significant OR if the scatter plot does not show a linear trend, the line should not be used for prediction.
- If [latex]r[/latex] is significant and if the scatter plot shows a linear trend, the line may NOT be appropriate or reliable for prediction OUTSIDE the domain of observed [latex]x[/latex] values in the data.
PERFORMING THE HYPOTHESIS TEST
- Null Hypothesis: [latex]H_0: \rho = 0[/latex]
- Alternate Hypothesis: [latex]H_a: \rho \neq 0[/latex]
WHAT THE HYPOTHESES MEAN IN WORDS:
- Null Hypothesis [latex]H_0[/latex]: The population correlation coefficient IS NOT significantly different from zero. There IS NOT a significant linear relationship(correlation) between x and y in the population.
- Alternate Hypothesis [latex]H_a[/latex]: The population correlation coefficient IS significantly DIFFERENT FROM zero. There IS A SIGNIFICANT LINEAR RELATIONSHIP (correlation) between x and y in the population.
DRAWING A CONCLUSION: There are two methods of making the decision. The two methods are equivalent and give the same result.
- Method 1: Using the p-value
- Method 2: Using a table of critical values
In this chapter of this textbook, we will always use a significance level of 5%, [latex]\alpha = 0.05[/latex].
Note
Using the p-value method, you could choose any appropriate significance level you want; you are not limited to using [latex]\alpha = 0.05[/latex]. But the table of critical values provided in this textbook assumes that we are using a significance level of 5%, [latex]\alpha = 0.05[/latex]. (If we wanted to use a different significance level than 5% with the critical value method, we would need different tables of critical values that are not provided in this textbook.)
METHOD 1: Using a p-value to make a decision
To calculate the p-value using LinRegTTEST:
On the LinRegTTEST input screen, on the line prompt for β or ρ, highlight “≠ 0”
The output screen shows the p-value on the line that reads “p =”.
(Most computer statistical software can calculate the p-value.)
- Decision: Reject the null hypothesis.
- Conclusion: “There is sufficient evidence to conclude that there is a significant linear relationship between x and y because the correlation coefficient is significantly different from zero.”
- Decision: DO NOT REJECT the null hypothesis.
- Conclusion: “There is insufficient evidence to conclude that there is a significant linear relationship between x and y because the correlation coefficient is NOT significantly different from zero.”
- You will use technology to calculate the p-value. The following describes the calculations to compute the test statistics and the p-value:
- The p-value is calculated using a t-distribution with n – 2 degrees of freedom.
- The formula for the test statistic is [latex]t=\frac{r\sqrt{n-2}}{\sqrt{1-{r}^{2}}}[/latex]. The value of the test statistic, t, is shown in the computer or calculator output along with the p-value. The test statistic t has the same sign as the correlation coefficient r.
- The p-value is the combined area in both tails.
An alternative way to calculate the p-value [latex](p)[/latex] given by LinRegTTest is the command 2*tcdf(abs(t),10^99, n-2) in 2nd DISTR.
Examples
Third-Exam vs. Final-Exam Example: p-value method
Consider the third exam/final exam example in Section 10.2.
- The line of best fit is: [latex]\hat{y} = -173.51 + 4.83x[/latex] with [latex]r = 0.6631[/latex] and there are [latex]n = 11[/latex] data points.
- Can the regression line be used for prediction? Given a third exam score ([latex]x[/latex] value), can we use the line to predict the final exam score (predicted [latex]y[/latex] value)?
- [latex]H_0: \rho = 0[/latex]
- [latex]H_a: \rho \neq 0[/latex]
- [latex]\alpha = 0.05[/latex]
- The p-value is 0.026 (from LinRegTTest on your calculator or from computer software).
- The p-value, 0.026, is less than the significance level of [latex]\alpha = 0.05[/latex].
- Decision: Reject the Null Hypothesis [latex]H_0[/latex]
- Conclusion: There is sufficient evidence to conclude that there is a significant linear relationship between the third exam score ([latex]x[/latex]) and the final exam score ([latex]y[/latex]) because the correlation coefficient is significantly different from zero.
Because [latex]r[/latex] is significant and the scatter plot shows a linear trend, the regression line can be used to predict final exam scores.
METHOD 2: Using a table of Critical Values to make a decision
The 95% Critical Values of the Sample Correlation Coefficient Table can be used to give you a good idea of whether the computed value of [latex]r[/latex] is significant or not. Compare [latex]r[/latex] to the appropriate critical value in the table. If [latex]r[/latex] is not between the positive and negative critical values, then the correlation coefficient is significant. If [latex]r[/latex] is significant, then you may want to use the line for prediction.
Example
Suppose you computed [latex]r = 0.801[/latex] using [latex]n = 10[/latex] data points, [latex]df = n - 2 = 10 - 2 = 8[/latex]. The critical values associated with [latex]df = 8[/latex] are [latex]-0.632[/latex] and [latex]+0.632[/latex]. If [latex]r \lt \text{negative critical value}[/latex] or [latex]r > \text{positive critical value}[/latex], then [latex]r[/latex] is significant. Since [latex]r = 0.801[/latex] and [latex]0.801 > 0.632[/latex], [latex]r[/latex] is significant and the line may be used for prediction. If you view this example on a number line, it will help you.

Your Turn!
For a given line of best fit, you computed that [latex]r = 0.6501[/latex] using [latex]n = 12[/latex] data points and the critical value is [latex]0.576[/latex]. Can the line be used for prediction? Why or why not?
Solution
If the scatter plot looks linear then, yes, the line can be used for prediction, because [latex]r > \text{the positive critical value}[/latex].
Example
Suppose you computed [latex]r = –0.624[/latex] with 14 data points. [latex]df = 14 – 2 = 12[/latex]. The critical values are [latex]–0.532[/latex] and [latex]0.532[/latex]. Since [latex]–0.624 \lt –0.532[/latex], [latex]r[/latex] is significant and the line can be used for prediction

Your Turn!
For a given line of best fit, you compute that [latex]r = 0.5204[/latex] using [latex]n = 9[/latex] data points, and the critical value is [latex]0.666[/latex]. Can the line be used for prediction? Why or why not?
Solution
No, the line cannot be used for prediction, because [latex]r \lt \text{the positive critical value}[/latex].
Example
Suppose you computed [latex]r = 0.776[/latex] and [latex]n = 6[/latex]. [latex]df = 6 – 2 = 4[/latex]. The critical values are [latex]–0.811[/latex] and [latex]0.811[/latex]. Since [latex]–0.811 \lt 0.776 \lt 0.811[/latex], [latex]r[/latex] is not significant, and the line should not be used for prediction.

Your Turn!
For a given line of best fit, you compute that [latex]r = –0.7204[/latex] using [latex]n = 8[/latex] data points, and the critical value is [latex]0.707[/latex]. Can the line be used for prediction? Why or why not?
Solution
Yes, the line can be used for prediction, because [latex]r \lt \text{the negative critical value}[/latex].
Third-Exam vs. Final-Exam Example: critical value method
Consider the third exam/final exam example from Section 10.2.
The line of best fit is: [latex]\hat{y} = –173.51+4.83x[/latex] with [latex]r = 0.6631[/latex] and there are [latex]n = 11[/latex] data points. Can the regression line be used for prediction? Given a third-exam score ([latex]x[/latex] value), can we use the line to predict the final exam score (predicted y value)?
- [latex]H_0: \rho = 0[/latex]
- [latex]H_a: \rho \neq 0[/latex]
- [latex]\alpha = 0.05[/latex]
- Use the “95% Critical Value” table for [latex]r[/latex] with [latex]df = n – 2 = 11 – 2 = 9[/latex].
- The critical values are [latex]–0.602[/latex] and [latex]+0.602[/latex].
- Since [latex]0.6631 > 0.602[/latex], [latex]r[/latex] is significant.
- Decision: Reject the null hypothesis.
- Conclusion: There is sufficient evidence to conclude that there is a significant linear relationship between the third exam score ([latex]x[/latex]) and the final exam score ([latex]y[/latex]) because the correlation coefficient is significantly different from zero.
Because [latex]r[/latex] is significant and the scatter plot shows a linear trend, the regression line can be used to predict final exam scores.
Example
Suppose you computed the following correlation coefficients. Using the table at the end of the chapter, determine if [latex]r[/latex] is significant and the line of best fit associated with each [latex]r[/latex] can be used to predict a [latex]y[/latex] value. If it helps, draw a number line.
- [latex]r = –0.567[/latex] and the sample size [latex]n=19[/latex]. The [latex]df = n – 2 = 17[/latex]. The critical value is [latex]–0.456[/latex]. Since [latex]–0.567 \lt –0.456[/latex], [latex]r[/latex] is significant.
- [latex]r = 0.708[/latex] and the sample size [latex]n=9[/latex]. The [latex]df = n – 2 = 7[/latex]. The critical value is [latex]0.666[/latex]. Since [latex]0.708 > 0.666[/latex], [latex]r[/latex] is significant.
- [latex]r = 0.134[/latex] and the sample size [latex]n = 14[/latex]. The [latex]df = 14 – 2 = 12[/latex]. The critical value is [latex]0.532[/latex]. Since [latex]–0.532 \lt 0.134 \lt 0.532[/latex], [latex]r[/latex] is not significant.
- [latex]r = 0[/latex] and the sample size [latex]n = 5[/latex]. No matter what the [latex]df \text{s}[/latex] are, [latex]r = 0[/latex] is between the two critical values, so [latex]r[/latex] is not significant.
Your Turn!
For a given line of best fit, you compute that [latex]r = 0[/latex] using [latex]n = 100[/latex] data points. Can the line be used for prediction? Why or why not?
Solution
No, the line cannot be used for prediction no matter what the sample size is.
Assumptions in Testing the Significance of the Correlation Coefficient
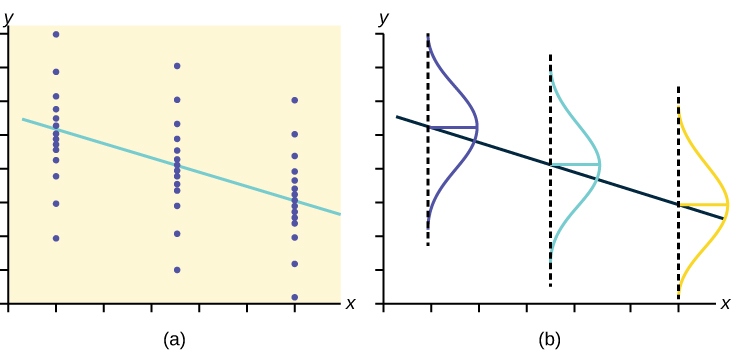
Testing the significance of the correlation coefficient requires that certain assumptions about the data are satisfied. The premise of this test is that the data are a sample of observed points taken from a larger population. We have not examined the entire population because it is not possible or feasible to do so. We are examining the sample to draw a conclusion about whether the linear relationship that we see between [latex]x[/latex] and [latex]y[/latex] in the sample data provides strong enough evidence so that we can conclude that there is a linear relationship between [latex]x[/latex] and [latex]y[/latex] in the population.
The regression line equation that we calculate from the sample data gives the best-fit line for our particular sample. We want to use this best-fit line for the sample as an estimate of the best-fit line for the population. Examining the scatterplot and testing the significance of the correlation coefficient helps us determine if it is appropriate to do this.
- There is a linear relationship in the population that models the average value of [latex]y[/latex] for varying values of [latex]x[/latex]. In other words, the expected value of [latex]y[/latex] for each particular value lies on a straight line in the population. (We do not know the equation for the line for the population. Our regression line from the sample is our best estimate of this line in the population.)
- The [latex]y[/latex] values for any particular [latex]x[/latex] value are normally distributed about the line. This implies that there are more [latex]y[/latex] values scattered closer to the line than are scattered farther away. Assumption 1 implies that these normal distributions are centered on the line: the means of these normal distributions of [latex]y[/latex] values lie on the line.
- The standard deviations of the population [latex]y[/latex] values about the line are equal for each value of [latex]x[/latex]. In other words, each of these normal distributions of [latex]y[/latex] values has the same shape and spread about the line.
- The residual errors are mutually independent (no pattern).
- The data are produced from a well-designed, random sample or randomized experiment.
Section 10.4 Review
Linear regression is a procedure for fitting a straight line of the form [latex]\hat{y} = a + bx[/latex] to data. The conditions for regression are:
- Linear: In the population, there is a linear relationship that models the average value of [latex]y[/latex] for different values of [latex]x[/latex].
- Independent: The residuals are assumed to be independent.
- Normal: The [latex]y[/latex] values are distributed normally for any value of [latex]x[/latex].
- Equal variance: The standard deviation of the [latex]y[/latex] values is equal for each [latex]x[/latex] value.
- Random: The data are produced from a well-designed random sample or randomized experiment.
The slope [latex]b[/latex] and intercept [latex]a[/latex] of the least-squares line estimate the slope [latex]\beta[/latex] and intercept [latex]\alpha[/latex] of the population (true) regression line. To estimate the population standard deviation of [latex]y[/latex], [latex]\sigma[/latex], use the standard deviation of the residuals, [latex]s[/latex]. [latex]s=\sqrt{\frac{SEE}{n-2}}[/latex]. The variable [latex]\rho[/latex] (rho) is the population correlation coefficient.
To test the null hypothesis
[latex]H_0: \rho =[/latex]hypothesized value, use a linear regression t-test. The most common null hypothesis is [latex]H_0: \rho = 0[/latex] which indicates there is no linear relationship between [latex]x[/latex] and [latex]y[/latex] in the population. The TI-83, 83+, 84, 84+ calculator function LinRegTTest can perform this test (STATS TESTS LinRegTTest).
Formula Review
- Least Squares Line or Line of Best Fit: [latex]\hat{y}=a+bx[/latex], where [latex]a = \text{y-intercept}[/latex] and [latex]b = \text{slope}[/latex]
- Standard deviation of the residuals: [latex]s=\sqrt{\frac{SEE}{n-2}}[/latex], where [latex]SSE = \text{sum of squared errors}[/latex] and [latex]n = \text{the number of data points}[/latex]
Section 10.4 Practice
1. When testing the significance of the correlation coefficient, what is the null hypothesis?
2. When testing the significance of the correlation coefficient, what is the alternative hypothesis?
Solution
[latex]H_a: \rho \neq 0[/latex]
1. If the level of significance is 0.05 and the p-value is 0.04, what conclusion can you draw?
2. If the level of significance is 0.05 and the p-value is 0.06, what conclusion can you draw?
Solution
We do not reject the null hypothesis. There is not sufficient evidence to conclude that there is a significant linear relationship between [latex]x[/latex] and [latex]y[/latex] because the correlation coefficient is not significantly different from zero.
If there are 15 data points in a set of data, what is the number of degrees of freedom?
