Chapter 2: Descriptive Statistics
2.3 Measures of the Location of the Data
Learning Objectives
By the end of this section, the student should be able to:
- Recognize, describe, and calculate the measures of location of data: quartiles and percentiles.
- Compute the five-number summary.
The common measures of location are quartiles and percentiles
Quartiles are special percentiles. The first quartile, [latex]Q_1[/latex], is the same as the 25th percentile, and the third quartile, [latex]Q_3[/latex], is the same as the 75th percentile. The median, [latex]M[/latex], is called both the second quartile and the 50th percentile.
To calculate quartiles and percentiles, the data must be ordered from smallest to largest. Quartiles divide ordered data into quarters. Percentiles divide ordered data into hundredths. To score in the 90th percentile of an exam does not mean, necessarily, that you received 90% on a test. It means that 90% of test scores are the same or less than your score and 10% of the test scores are the same or greater than your test score.
Percentiles are useful for comparing values. For this reason, universities and colleges use percentiles extensively. One instance in which colleges and universities use percentiles is when SAT results are used to determine a minimum testing score that will be used as an acceptance factor. For example, suppose Duke accepts SAT scores at or above the 75th percentile. That translates into a score of at least 1220.
Percentiles are mostly used with very large populations. Therefore, if you were to say that 90% of the test scores are less (and not the same or less) than your score, it would be acceptable because removing one particular data value is not significant.
The median is a number that measures the "center" of the data. You can think of the median as the "middle value," but it does not actually have to be one of the observed values. It is a number that separates ordered data into halves. Half the values are the same number or smaller than the median, and half the values are the same number or larger. For example, consider the following data.
1; 11.5; 6; 7.2; 4; 8; 9; 10; 6.8; 8.3; 2; 2; 10; 1
Ordered from smallest to largest:
1; 1; 2; 2; 4; 6; 6.8; 7.2; 8; 8.3; 9; 10; 10; 11.5
Since there are 14 observations, the median is between the seventh value, 6.8, and the eighth value, 7.2. To find the median, add the two values together and divide by two.
The median is seven. Half of the values are smaller than seven and half of the values are larger than seven.
Quartiles are numbers that separate the data into quarters. Quartiles may or may not be part of the data. To find the quartiles, first find the median or second quartile. The first quartile, Q1, is the middle value of the lower half of the data, and the third quartile, Q3, is the middle value, or median, of the upper half of the data. To get the idea, consider the same data set:
1; 1; 2; 2; 4; 6; 6.8; 7.2; 8; 8.3; 9; 10; 10; 11.5
The median or second quartile is seven. The lower half of the data are 1, 1, 2, 2, 4, 6, 6.8. The middle value of the lower half is two.
1; 1; 2; 2; 4; 6; 6.8
The number two, which is part of the data, is the first quartile. One-fourth of the entire sets of values are the same as or less than two and three-fourths of the values are more than two.
The upper half of the data is 7.2, 8, 8.3, 9, 10, 10, 11.5. The middle value of the upper half is nine.
The third quartile, Q3, is nine. Three-fourths (75%) of the ordered data set are less than nine. One-fourth (25%) of the ordered data set are greater than nine. The third quartile is part of the data set in this example.
The interquartile range is a number that indicates the spread of the middle half or the middle 50% of the data. It is the difference between the third quartile (Q3) and the first quartile (Q1).
IQR = Q3 – Q1
The IQR can help to determine potential outliers. A value is suspected to be a potential outlier if it is less than (1.5)(IQR) below the first quartile or more than (1.5)(IQR) above the third quartile. Potential outliers always require further investigation.
Note
A potential outlier is a data point that is significantly different from the other data points. These special data points may be errors or some kind of abnormality or they may be a key to understanding the data.
Example
For the following 13 real estate prices, calculate the IQR and determine if any prices are potential outliers. Prices are in dollars.
389,950; 230,500; 158,000; 479,000; 639,000; 114,950; 5,500,000; 387,000; 659,000; 529,000; 575,000; 488,800; 1,095,000
Solution
Order the data from smallest to largest.
114,950; 158,000; 230,500; 387,000; 389,950; 479,000; 488,800; 529,000; 575,000; 639,000; 659,000; 1,095,000; 5,500,000
[latex]M = 488,800[/latex]
[latex]Q_1 = \frac{\text{230,500 + 387,000}}{2} = 308,750[/latex]
[latex]Q_3 = \frac{\text{639,000 + 659,000}}{2} = 649,000[/latex]
[latex]IQR = 649,000 – 308,750 = 340,250[/latex]
[latex](1.5)(IQR) = (1.5)(340,250) = 510,375[/latex]
[latex]Q_1 – (1.5)(IQR) = 308,750 – 510,375 = –201,625[/latex]
[latex]Q_3 + (1.5)(IQR) = 649,000 + 510,375 = 1,159,375[/latex]
No house price is less than –201,625. However, 5,500,000 is more than 1,159,375. Therefore, 5,500,000 is a potential outlier.
Your Turn!
For the following 11 salaries, calculate the IQR and determine if any salaries are outliers. The salaries are in dollars.
$33,000; $64,500; $28,000; $54,000; $72,000; $68,500; $69,000; $42,000; $54,000; $120,000; $40,500
Solution
Order the data from smallest to largest.
$28,000; $33,000; $40,500; $42,000; $54,000; $54,000; $64,500; $68,500; $69,000; $72,000; $120,000
[latex]\text{Median} = 54,000[/latex]
[latex]Q_1 = 40,500[/latex]
[latex]Q_3 = 69,000[/latex]
[latex]IQR = 69,000 – 40,500 = 28,500[/latex]
[latex](1.5)(IQR) = (1.5)(28,500) = 42,750[/latex]
[latex]Q_1 – (1.5)(IQR) = 40,500 – 42,750 = –2,250[/latex]
[latex]Q_3 + (1.5)(IQR) = 69,000 + 42,750 = 111,750[/latex]
No salary is less than –$2,250. However, $120,000 is more than $11,750, so $120,000 is a potential outlier.
Example
For the two data sets in the test scores example at the beginning of this section, find the following:
- The interquartile range. Compare the two interquartile ranges.
- Any outliers in either set.
Solution
The five number summary for the day and night classes is
| Minimum | Q1 | Median | Q3 | Maximum | |
|---|---|---|---|---|---|
| Day | 32 | 56 | 74.5 | 82.5 | 99 |
| Night | 25.5 | 78 | 81 | 89 | 98 |
- The IQR for the day group is [latex]Q_3 – Q_1 = 82.5 – 56 = 26.5[/latex]
The IQR for the night group is [latex]Q_3 – Q_1 = 89 – 78 = 11[/latex]
The interquartile range (the spread or variability) for the day class is larger than the night class IQR. This suggests more variation will be found in the day class’s class test scores.
- Day class outliers are found using the IQR times 1.5 rule. So,
- [latex]Q_1 - IQR(1.5) = 56 – 26.5(1.5) = 16.25[/latex]
- [latex]Q_3 + IQR(1.5) = 82.5 + 26.5(1.5) = 122.25[/latex]
Since the minimum and maximum values for the day class are greater than 16.25 and less than 122.25, there are no outliers.
Night class outliers are calculated as:
- [latex]Q_1 – IQR (1.5) = 78 – 11(1.5) = 61.5[/latex]
- [latex]Q_3 + IQR(1.5) = 89 + 11(1.5) = 105.5[/latex]
For this class, any test score less than 61.5 is an outlier. Therefore, the scores of 45 and 25.5 are outliers. Since no test score is greater than 105.5, there is no upper end outlier.
Your Turn!
Find the interquartile range for the following two data sets and compare them.
Test Scores for Class A
69; 96; 81; 79; 65; 76; 83; 99; 89; 67; 90; 77; 85; 98; 66; 91; 77; 69; 80; 94
Test Scores for Class B
90; 72; 80; 92; 90; 97; 92; 75; 79; 68; 70; 80; 99; 95; 78; 73; 71; 68; 95; 100
Solution
Class A
Order the data from smallest to largest.
65; 66; 67; 69; 69; 76; 77; 77; 79; 80; 81; 83; 85; 89; 90; 91; 94; 96; 98; 99
[latex]\text{Median}=\frac{80+81}{2}=80.5[/latex]
[latex]{Q}_{1}=\frac{69+76}{2}=72.5[/latex]
[latex]{Q}_{3}=\frac{90+91}{2}=90.5[/latex]
[latex]IQR = 90.5 – 72.5 = 18[/latex]
Class B
Order the data from smallest to largest.
68; 68; 70; 71; 72; 73; 75; 78; 79; 80; 80; 90; 90; 92; 92; 95; 95; 97; 99; 100
[latex]\text{Median}=\frac{80+80}{2}=80[/latex]
[latex]{Q}_{1}=\frac{72+73}{2}=72.5[/latex]
[latex]{Q}_{3}=\frac{92+95}{2}=93.5[/latex]
[latex]IQR = 93.5 – 72.5 = 21[/latex]
The data for Class B has a larger IQR, so the scores between [latex]Q_3[/latex] and [latex]Q_1[/latex] (middle 50%) for the data for Class B are more spread out and not clustered about the median.
Example
Fifty statistics students were asked how much sleep they get per school night (rounded to the nearest hour). The results were:
| AMOUNT OF SLEEP PER SCHOOL NIGHT (HOURS) | FREQUENCY | RELATIVE FREQUENCY | CUMULATIVE RELATIVE FREQUENCY |
|---|---|---|---|
| 4 | 2 | 0.04 | 0.04 |
| 5 | 5 | 0.10 | 0.14 |
| 6 | 7 | 0.14 | 0.28 |
| 7 | 12 | 0.24 | 0.52 |
| 8 | 14 | 0.28 | 0.80 |
| 9 | 7 | 0.14 | 0.94 |
| 10 | 3 | 0.06 | 1.00 |
Find the 28th percentile. Notice the 0.28 in the "cumulative relative frequency" column. Twenty-eight percent of 50 data values is 14 values. There are 14 values less than the 28th percentile. They include the two 4s, the five 5s, and the seven 6s. The 28th percentile is between the last six and the first seven. The 28th percentile is 6.5.
Find the median. Look again at the "cumulative relative frequency" column and find 0.52. The median is the 50th percentile or the second quartile. 50% of 50 is 25. There are 25 values less than the median. They include the two 4s, the five 5s, the seven 6s, and eleven of the 7s. The median or 50th percentile is between the 25th, or seven, and 26th, or seven, values. The median is seven.
Find the third quartile. The third quartile is the same as the 75th percentile. You can "eyeball" this answer. If you look at the "cumulative relative frequency" column, you find 0.52 and 0.80. When you have all the fours, fives, sixes and sevens, you have 52% of the data. When you include all the 8s, you have 80% of the data. The 75th percentile, then, must be an eight. Another way to look at the problem is to find 75% of 50, which is 37.5, and round up to 38. The third quartile, [latex]Q_3[/latex], is the 38th value, which is an eight. You can check this answer by counting the values. (There are 37 values below the third quartile and 12 values above.)
Your Turn!
Forty bus drivers were asked how many hours they spend each day running their routes (rounded to the nearest hour). Find the 65th percentile.
| Amount of time spent on route (hours) | Frequency | Relative Frequency | Cumulative Relative Frequency |
|---|---|---|---|
| 2 | 12 | 0.30 | 0.30 |
| 3 | 14 | 0.35 | 0.65 |
| 4 | 10 | 0.25 | 0.90 |
| 5 | 4 | 0.10 | 1.00 |
Solution
The 65th percentile is between the last three and the first four.
The 65th percentile is 3.5.
A Formula for Finding the kth Percentile
If you were to do a little research, you would find several formulas for calculating the kth percentile. Here is one of them.
[latex]k =[/latex] the kth percentile. It may or may not be part of the data.
[latex]i =[/latex] the index (ranking or position of a data value)
[latex]n =[/latex] the total number of data
- Order the data from smallest to largest.
- Calculate [latex]i=\frac{k}{100}\left(n+1\right)[/latex]
- If [latex]i[/latex] is an integer, then the [latex]k^{th}[/latex] percentile is the data value in the [latex]i^{th}[/latex] position in the ordered set of data.
- If [latex]i[/latex] is not an integer, then round [latex]i[/latex] up and round [latex]i[/latex] down to the nearest integers. Average the two data values in these two positions in the ordered data set. This is easier to understand in an example.
Example
Listed are 29 ages for Academy Award winning best actors in order from smallest to largest.
18; 21; 22; 25; 26; 27; 29; 30; 31; 33; 36; 37; 41; 42; 47; 52; 55; 57; 58; 62; 64; 67; 69; 71; 72; 73; 74; 76; 77
- Find the 70th percentile.
- Find the 83rd percentile.
Solution
-
- [latex]k = 70[/latex]
- [latex]i =[/latex] the index
- [latex]n = 29[/latex]
1. [latex]i = \frac{k}{100} (n + 1) = (\frac{70}{100})(29 + 1) = 21[/latex] Twenty-one is an integer, and the data value in the 21st position in the ordered data set is 64. The 70th percentile is 64 years.
- [latex]k =[/latex]83rd percentile
- [latex]i =[/latex] the index
- [latex]n = 29[/latex]
- [latex]i = \frac{k}{100} (n + 1) = (\frac{83}{100})(29 + 1) = 24.9[/latex], which is NOT an integer. Round it down to 24 and up to 25. The age in the 24th position is 71 and the age in the 25th position is 72. Average 71 and 72. The 83rd percentile is 71.5 years.
Your Turn!
Listed are 29 ages for Academy Award winning best actors in order from smallest to largest.
18; 21; 22; 25; 26; 27; 29; 30; 31; 33; 36; 37; 41; 42; 47; 52; 55; 57; 58; 62; 64; 67; 69; 71; 72; 73; 74; 76; 77
Calculate the 20th percentile and the 55th percentile.
Solution
[latex]k = 20.[/latex] [latex]\text{Index} = i = \frac{k}{100}\left(n+1\right)=\frac{20}{100}(29 + 1) = 6[/latex]. The age in the sixth position is 27. The 20th percentile is 27 years.
[latex]k = 55.[/latex] [latex]\text{Index} = i = \frac{k}{100}\left(n+1\right)=\frac{55}{100}(29 + 1) = 16.5[/latex]. Round down to 16 and up to 17. The age in the 16th position is 52 and the age in the 17th position is 55. The average of 52 and 55 is 53.5. The 55th percentile is 53.5 years.
Note
You can calculate percentiles using calculators and computers. There are a variety of online calculators.
A Formula for Finding the Percentile of a Value in a Data Set
- Order the data from smallest to largest.
- [latex]x =[/latex]the number of data values counting from the bottom of the data list up to but not including the data value for which you want to find the percentile.
- [latex]y =[/latex] the number of data values equal to the data value for which you want to find the percentile.
- [latex]n =[/latex] the total number of data.
- Calculate [latex]\frac{x+0.5y}{n}(100)[/latex]. Then round to the nearest integer.
Example
Listed are 29 ages for Academy Award winning best actors in order from smallest to largest.
18; 21; 22; 25; 26; 27; 29; 30; 31; 33; 36; 37; 41; 42; 47; 52; 55; 57; 58; 62; 64; 67; 69; 71; 72; 73; 74; 76; 77
- Find the percentile for 58.
- Find the percentile for 25.
Solution
- Counting from the bottom of the list, there are 18 data values less than 58. There is one value of 58.
[latex]x = 18[/latex] and [latex]y = 1[/latex].[latex]\frac{x+0.5y}{n}(100) = \frac{18+0.5\left(1\right)}{29}(100) = 63.80[/latex]. 58 is the 64th percentile.
- Counting from the bottom of the list, there are three data values less than 25. There is one value of 25.
[latex]x = 3[/latex] and [latex]y = 1[/latex].[latex]\frac{x+0.5y}{n}(100) = \frac{3+0.5\left(1\right)}{29}(100) = 12.07[/latex]. Twenty-five is the 12th percentile.
Your Turn!
Listed are 30 ages for Academy Award winning best actors in order from smallest to largest.
18; 21; 22; 25; 26; 27; 29; 30; 31; 31; 33; 36; 37; 41; 42; 47; 52; 55; 57; 58; 62; 64; 67; 69; 71; 72; 73; 74; 76; 77
Find the percentiles for 47 and 31.
Solution
Percentile for 47: Counting from the bottom of the list, there are 15 data values less than 47. There is one value of 47.
[latex]x = 15[/latex] and [latex]y = 1[/latex].[latex]\frac{x+0.5y}{n}(100) = \frac{15+0.5\left(1\right)}{30}(100) = 51.89[/latex]. 47 is the 52nd percentile.
Percentile for 31: Counting from the bottom of the list, there are eight data values less than 31. There are two values of 31.
[latex]x = 8[/latex] and [latex]y = 2[/latex]. [latex]\frac{x+0.5y}{n}(100) = \frac{8+0.5\left(2\right)}{30}(100) = 27[/latex]. 31 is the 27th percentile.
Interpreting Percentiles, Quartiles, and Median
A percentile indicates the relative standing of a data value when data are sorted into numerical order from smallest to largest. Percentages of data values are less than or equal to the [latex]p^{th}[/latex] percentile. For example, 15% of data values are less than or equal to the 15th percentile.
- Low percentiles always correspond to lower data values.
- High percentiles always correspond to higher data values.
A percentile may or may not correspond to a value judgment about whether it is "good" or "bad." The interpretation of whether a certain percentile is "good" or "bad" depends on the context of the situation to which the data applies. In some situations, a low percentile would be considered "good"; in other contexts a high percentile might be considered "good." In many situations, there is no value judgment that applies.
Understanding how to interpret percentiles properly is important not only when describing data, but also when calculating probabilities in later chapters of this text.
When writing the interpretation of a percentile in the context of the given data, the sentence should contain the following information.
- information about the context of the situation being considered
- the data value (value of the variable) that represents the percentile
- the percent of individuals or items with data values below the percentile
- the percent of individuals or items with data values above the percentile.
Example
On a timed math test, the first quartile for time it took to finish the exam was 35 minutes. Interpret the first quartile in the context of this situation.
Solution
-
- Twenty-five percent of students finished the exam in 35 minutes or less.
- Seventy-five percent of students finished the exam in 35 minutes or more.
- A low percentile could be considered good, as finishing more quickly on a timed exam is desirable. (If you take too long, you might not be able to finish.)
Your Turn!
For the 100-meter dash, the third quartile for times for finishing the race was 11.5 seconds. Interpret the third quartile in the context of the situation.
Solution
Twenty-five percent of runners finished the race in 11.5 seconds or more. Seventy-five percent of runners finished the race in 11.5 seconds or less. A lower percentile is good because finishing a race more quickly is desirable.
Example
On a 20 question math test, the 70th percentile for the number of correct answers was 16. Interpret the 70th percentile in the context of this situation.
Solution
Seventy percent of students answered 16 or fewer questions correctly.
- Thirty percent of students answered 16 or more questions correctly.
- A higher percentile could be considered good, as answering more questions correctly is desirable.
Your Turn!
On a 60 point written assignment, the 80th percentile for the number of points earned was 49. Interpret the 80th percentile in the context of this situation.
Solution
Eighty percent of students earned 49 points or fewer. Twenty percent of students earned 49 or more points. A higher percentile is good because getting more points on an assignment is desirable.
Example
At a community college, it was found that the 30th percentile of credit units that students are enrolled for is seven units. Interpret the 30th percentile in the context of this situation.
Solution
Thirty percent of students are enrolled in seven or fewer credit units.
- Seventy percent of students are enrolled in seven or more credit units.
- In this example, there is no "good" or "bad" value judgment associated with a higher or lower percentile. Students attend community college for varied reasons and needs, and their course load varies according to their needs.
Your Turn!
During a season, the 40th percentile for points scored per player in a game is eight. Interpret the 40th percentile in the context of this situation.
Solution
Forty percent of players scored eight points or fewer. Sixty percent of players scored eight points or more. A higher percentile is good because getting more points in a basketball game is desirable.
Example
Sharpe Middle School is applying for a grant that will be used to add fitness equipment to the gym. The principal surveyed 15 anonymous students to determine how many minutes a day the students spend exercising. The results from the 15 anonymous students are shown.
0 minutes; 40 minutes; 60 minutes; 30 minutes; 60 minutes
10 minutes; 45 minutes; 30 minutes; 300 minutes; 90 minutes;
30 minutes; 120 minutes; 60 minutes; 0 minutes; 20 minutes
Determine the following five values.
- [latex]\text{Min} = 0[/latex]
- [latex]Q_1 = 20[/latex]
- [latex]\text{Med} = 40[/latex]
- [latex]Q_3 = 60[/latex]
- [latex]\text{Max} = 300[/latex]
If you were the principal, would you be justified in purchasing new fitness equipment? Since 75% of the students exercise for 60 minutes or less daily, and since the IQR is 40 minutes (60 – 20 = 40), we know that half of the students surveyed exercise between 20 minutes and 60 minutes daily. This seems a reasonable amount of time spent exercising, so the principal would be justified in purchasing the new equipment.
However, the principal needs to be careful. The value 300 appears to be a potential outlier.
[latex]Q_3 + 1.5(IQR) = 60 + (1.5)(40) = 120[/latex]
The value 300 is greater than 120 so it is a potential outlier. If we delete it and calculate the five values, we get the following values:
- [latex]\text{Min} = 0[/latex]
- [latex]Q_1 = 20[/latex]
- [latex]\text{Med}=35[/latex]
- [latex]Q_3 = 60[/latex]
- [latex]\text{Max} = 120[/latex]
We still have 75% of the students exercising for 60 minutes or less daily and half of the students exercising between 20 and 60 minutes a day. However, 15 students is a small sample and the principal should survey more students to be sure of his survey results.
Section 2.3 Review
The values that divide a rank-ordered set of data into 100 equal parts are called percentiles. Percentiles are used to compare and interpret data. For example, an observation at the 50th percentile would be greater than 50 percent of the other observations in the set. Quartiles divide data into quarters. The first quartile (Q1) is the 25th percentile, the second quartile (Q2 or median) is 50th percentile, and the third quartile (Q3) is the 75th percentile. The interquartile range, or IQR, is the range of the middle 50 percent of the data values. The IQR is found by subtracting Q1 from Q3, and can help determine outliers by using the following two expressions.
- [latex]Q_3 + IQR(1.5)[/latex]
- [latex]Q_1 – IQR(1.5)[/latex]
Formula Review
- [latex]i=\left(\frac{k}{100}\right)\left(n+1\right)[/latex]
- where [latex]i =[/latex]the ranking or position of a data value,
- [latex]k =[/latex] the kth percentile,
- [latex]n =[/latex] total number of data.
- Expression for finding the percentile of a data value: [latex]\left(\frac{x\text{ + }0.5y}{n}\right)(100)[/latex], where
- [latex]x =[/latex] the number of values counting from the bottom of the data list up to but not including the data value for which you want to find the percentile,
- [latex]y =[/latex] the number of data values equal to the data value for which you want to find the percentile,
- [latex]n =[/latex] total number of data
Section 2.3 Practice
Listed are 29 ages for Academy Award winning best actors in order from smallest to largest.
18; 21; 22; 25; 26; 27; 29; 30; 31; 33; 36; 37; 41; 42; 47; 52; 55; 57; 58; 62; 64; 67; 69; 71; 72; 73; 74; 76; 77
- Find the 40th percentile.
- Find the 78th percentile.
Solution
- The 40th percentile is 37 years.
- The 78th percentile is 70 years.
Listed are 32 ages for Academy Award winning best actors in order from smallest to largest.
18; 18; 21; 22; 25; 26; 27; 29; 30; 31; 31; 33; 36; 37; 37; 41; 42; 47; 52; 55; 57; 58; 62; 64; 67; 69; 71; 72; 73; 74; 76; 77
- Find the percentile of 37.
- Find the percentile of 72.
Jesse was ranked 37th in his graduating class of 180 students. At what percentile is Jesse’s ranking?
Solution
Jesse graduated 37th out of a class of 180 students. There are [latex]180 – 37 = 143[/latex] students ranked below Jesse. There is one rank of 37.
[latex]x = 143[/latex] and [latex]y = 1[/latex]. [latex]\frac{x+0.5y}{n}[/latex](100) = [latex]\frac{143+0.5\left(1\right)}{180}[/latex](100) = 79.72. Jesse’s rank of 37 puts him at the 80th percentile.
- For runners in a race, a low time means a faster run. The winners in a race have the shortest running times. Is it more desirable to have a finish time with a high or a low percentile when running a race?
- The 20th percentile of run times in a particular race is 5.2 minutes. Write a sentence interpreting the 20th percentile in the context of the situation.
- A bicyclist in the 90th percentile of a bicycle race completed the race in 1 hour and 12 minutes. Is he among the fastest or slowest cyclists in the race? Write a sentence interpreting the 90th percentile in the context of the situation.
- For runners in a race, a higher percentile means a faster run. Is it more desirable to have a speed with a high or a low percentile when running a race?
- The 40th percentile of speeds in a particular race is 7.5 miles per hour. Write a sentence interpreting the 40th percentile in the context of the situation.
Solution
1. For runners in a race it is more desirable to have a high percentile for speed. A high percentile means a higher speed which is faster.
5. 40% of runners ran at speeds of 7.5 miles per hour or less (slower). 60% of runners ran at speeds of 7.5 miles per hour or more (faster).
Mina is waiting in line at the Department of Motor Vehicles (DMV). Her wait time of 32 minutes is the 85th percentile of wait times. Is that good or bad? Write a sentence interpreting the 85th percentile in the context of this situation.
Solution
When waiting in line at the DMV, the 85th percentile would be a long wait time compared to the other people waiting. 85% of people had shorter wait times than Mina. In this context, Mina would prefer a wait time corresponding to a lower percentile. 85% of people at the DMV waited 32 minutes or less. 15% of people at the DMV waited 32 minutes or longer.
In a study collecting data about the repair costs of damage to automobiles in a certain type of crash tests, a certain model of car had $1,700 in damage and was in the 90th percentile. Should the manufacturer and the consumer be pleased or upset by this result? Explain and write a sentence that interprets the 90th percentile in the context of this problem.
Solution
The manufacturer and the consumer would be upset. This is a large repair cost for the damages, compared to the other cars in the sample. INTERPRETATION: 90% of the crash tested cars had damage repair costs of $1700 or less; only 10% had damage repair costs of $1700 or more.
The University of California has two criteria used to set admission standards for freshman to be admitted to a college in the UC system:
- Students' GPAs and scores on standardized tests (SATs and ACTs) are entered into a formula that calculates an "admissions index" score. The admissions index score is used to set eligibility standards intended to meet the goal of admitting the top 12% of high school students in the state. In this context, what percentile does the top 12% represent?
- Students whose GPAs are at or above the 96th percentile of all students at their high school are eligible (called eligible in the local context), even if they are not in the top 12% of all students in the state. What percentage of students from each high school are "eligible in the local context"?
Suppose that you are buying a house. You and your realtor have determined that the most expensive house you can afford is the 34th percentile. The 34th percentile of housing prices is $240,000 in the town you want to move to. In this town, can you afford 34% of the houses or 66% of the houses?
Solution
You can afford 34% of houses. 66% of the houses are too expensive for your budget. INTERPRETATION: 34% of houses cost $240,000 or less. 66% of houses cost $240,000 or more.
The median age for U.S. blacks currently is 30.9 years; for U.S. whites it is 42.3 years.
Six hundred adult Americans were asked by telephone poll, "What do you think constitutes a middle-class income?" The results are in the table below. Also, include left endpoint, but not the right endpoint.
| Salary ($) | Relative Frequency |
|---|---|
| < 20,000 | 0.02 |
| 20,000–25,000 | 0.09 |
| 25,000–30,000 | 0.19 |
| 30,000–40,000 | 0.26 |
| 40,000–50,000 | 0.18 |
| 50,000–75,000 | 0.17 |
| 75,000–99,999 | 0.02 |
| 100,000+ | 0.01 |
- What percentage of the survey answered "not sure"?
- What percentage think that middle-class is from $25,000 to $50,000?
- Construct a histogram of the data.
- Should all bars have the same width, based on the data? Why or why not?
- How should the <20,000 and the 100,000+ intervals be handled? Why?
- Find the 40th and 80th percentiles
- Construct a bar graph of the data
Solution
- 1 – (0.02+0.09+0.19+0.26+0.18+0.17+0.02+0.01) = 0.06
- 0.19+0.26+0.18 = 0.63
- Check student’s solution.
-
40th percentile will fall between 30,000 and 40,000
80th percentile will fall between 50,000 and 75,000
- Check student’s solution.
Given the following box plot:

- which quarter has the smallest spread of data? What is that spread?
- which quarter has the largest spread of data? What is that spread?
- find the interquartile range (IQR).
- are there more data in the interval 5–10 or in the interval 10–13? How do you know this?
- which interval has the fewest data in it? How do you know this?
- 0–2
- 2–4
- 10–12
- 12–13
- need more information
The following box plot shows the U.S. population for 1990, the latest available year.
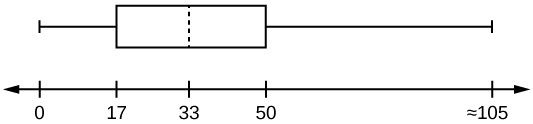
- Are there fewer or more children (age 17 and under) than senior citizens (age 65 and over)? How do you know?
- 12.6% are age 65 and over. Approximately what percentage of the population are working age adults (above age 17 to age 65)?
Solution
- more children; the left whisker shows that 25% of the population are children 17 and younger. The right whisker shows that 25% of the population are adults 50 and older, so adults 65 and over represent less than 25%.
- 62.4%
References
Cauchon, Dennis, Paul Overberg. “Census data shows minorities now a majority of U.S. births.” USA Today, 2012. Available online at http://usatoday30.usatoday.com/news/nation/story/2012-05-17/minority-birthscensus/55029100/1 (accessed April 3, 2013).
Data from the United States Department of Commerce: United States Census Bureau. Available online at http://www.census.gov/ (accessed April 3, 2013).
“1990 Census.” United States Department of Commerce: United States Census Bureau. Available online at http://www.census.gov/main/www/cen1990.html (accessed April 3, 2013).
Data from San Jose Mercury News.
Data from Time Magazine; survey by Yankelovich Partners, Inc.
the numbers that separate the data into quarters; quartiles may or may not be part of the data. The second quartile is the median of the data.
a number that divides ordered data into hundredths; percentiles may or may not be part of the data. The median of the data is the second quartile and the 50th percentile. The first and third quartiles are the 25th and the 75th percentiles, respectively.
or IQR, is the range of the middle 50 percent of the data values; the IQR is found by subtracting the first quartile from the third quartile.
an observation that does not fit the rest of the data
